LRU算法
LRU算法:Latest Recently Used
即我们认为最近访问的数据就是有用的,就应该更新到队头,这样的话,对尾的就应该是很久未被访问的数据。
这样就可以淘汰队尾的数据。
思路
缓存容量:初始化一个缓存容量。
添加数据:判断缓存是否已满?不满,新数据放表头;满,删除表尾数据,新数据放表头。
读取数据:判断数据是否存在?存在,放表头,返回数据;不存在,返回错误。
为了快,添加数据和读取数据的操作应为O(1)。
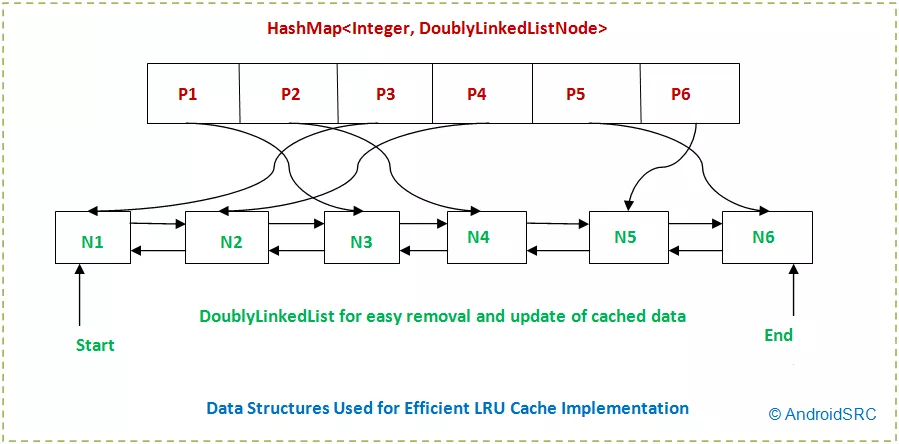
设计
实现该算法应满足:查找快,插入快,删除快,有顺序之分。
哈希表查找快,但数据无固定顺序;链表有顺序,插入删除快,但查找慢。
所以结合形成一种新的数据结构:哈希链表。
代码
链表节点
/**
* 链表节点
*/
public class Node {
Node pre;
Node next;
Object val;
String key;
}双向链表
public class DoubleLinkedList {
private int size;
private Node head = new Node();
private Node tail = new Node();
public DoubleLinkedList() {
head.pre = tail;
head.next = tail;
tail.pre = head;
tail.next = head;
this.size = 0;
}
//添加新节点
public void addFirst(Node node) {
node.next = head.next;
head.next.pre = node;
head.next = node;
node.pre = head;
++size;
}
//移除节点
public void remove(Node node) {
if (node != null) {
node.pre.next = node.next;
node.next.pre = node.pre;
--size;
}
}
//移除最后一个数据节点
public Node removeLast() {
if (tail.pre != head) {
Node last = tail.pre;
remove(last);
return last;
}
return null;
}
//获取当前缓存size
public int getSize() {
return this.size;
}
}
LRUCache
public class LRUCache {
private int capacity;
private final Map<String, Node> nodeMap;
private final DoubleLinkedList list;
public LRUCache(int capacity) {
this.capacity = capacity;
this.nodeMap = new HashMap<>(capacity);
this.list = new DoubleLinkedList();
}
//添加缓存
public void put(String key, Object val) {
Node node = new Node();
node.key = key;
node.val = val;
if (nodeMap.containsKey(key)) {
remove(key);
} else {
if (list.getSize() >= capacity) {
Node last = list.removeLast();
nodeMap.remove(last.key);
}
}
list.addFirst(node);
nodeMap.put(key, node);
}
//删除缓存
public void remove(String key) {
Node node = nodeMap.get(key);
if (node != null) {
list.remove(node);
nodeMap.remove(key);
}
}
//获取缓存
public Object get(String key) {
Node node = nodeMap.get(key);
if (node == null) {
return null;
}
put(node.key, node.val);
return node.val;
}
}测试
public class LRUTest {
public static void main(String[] args) {
LRUCache cache = new LRUCache( 2 /* 缓存容量 */ );
cache.put("1", 1);
cache.put("2", 2);
System.out.println(cache.get("1"));
cache.put("3", 3); // 该操作会使得关键字 2 作废
System.out.println(cache.get("2")); // 返回 null (未找到)
cache.put("4", 4); // 该操作会使得关键字 1 作废
System.out.println(cache.get("1")); // 返回 -1 (未找到)
System.out.println(cache.get("3")); // 返回 3
System.out.println(cache.get("4")); // 返回 3
}
}总结
为什么使用双向链表?
因为在删除节点时,需要获取前置节点,将前置节点的后置节点指向当前节点的后置节点。
如果是单相链表就无法更改。
为什么使用了哈希集合之后,链表中还需要存key?
因为在删除尾节点时,需要获取对应节点的key才可以将哈希中key与节点的映射关系删除,所以要从链表的节点中获取。