Java并发21-原子类:无锁工具类的典范
JDK提供了原子类,基本上是基于CAS原理实现的无锁下保证线程安全。
无锁
无锁方案相对互斥锁方案,最大的好处就是性能。
互斥锁方案为了保证互斥性,需要执行加锁、解锁操作,而加锁、解锁操作本身就消耗性能;
同时拿不到锁的线程还会进入阻塞状态,进而触发线程切换,线程切换对性能的消耗也很大。
而无锁方案则完全没有加锁、解锁的性能消耗,同时还能保证互斥性,相比互斥锁方案性能大大提升。
CAS
CAS即Compare And Swap,就是比较并交换。CAS是一种CPU指令,作为CPU指令,CAS本身是可以保证原子性的,所以CAS是通过硬件层面上的支持来保障数据更新的线程安全。
CAS有3个参数,共享变量内存地址A(旧值),用于比较值B(期望值),共享变量新值C(更新值)。只有当期望值B和旧值A相等时,才会将旧值更新为新值C。
如何理解这句话?
设有一值v=1,有多个线程同时对该值进行+1或-1操作。
CAS指令会先把旧值取出来,计算得到新值,并将旧值赋值给期望值。因为在计算新值的过程中,可能其他的线程已经将原内存地址的值修改过,所以需要通过更新值与当前内存地址的值进行比较,只有当期望值与内存地址的值相同时,才会将新值进行赋值。若期望值和内存地址的值不相同,那么说明已经有线程修改过该值了。所以当前线程的修改就失败了,这样保证了线程安全。
ABA问题
接上文,若期望值和内存地址值相同。是否能说明该值未被其他线程修改过?
在计算新值期间,v可能被加1又被减1,所以导致该值最终未发生变化,但实际上它是变化过的。这就是ABA问题。
原子类源码
我们取一个原子类底层的unsafe类的源码来看CAS在Java中如何实现的。
public final int getAndAddInt(Object this, long offset, int delta) {
int oldValue;
do {
oldValue = this.getIntVolatile(this, offset);
} while(!this.compareAndSwapInt(this, offset, oldValue, oldValue + delta));
return oldValue;
}首先,通过this和offset可以确定值的具体位置,delta是要增加的值。
代码先定位到值的位置,取出值作为oldValue,然后通过comapreAndSwap方法进行赋值。
其中参数this和offset可以定位值的内存地址,传入oldValue作为期望值,传入oldValue+delta作为新值。
只有当内存地址的值和期望值相等时才会将新值赋值,并返回true,结束循环。否则,返回false并继续自旋进行赋值。
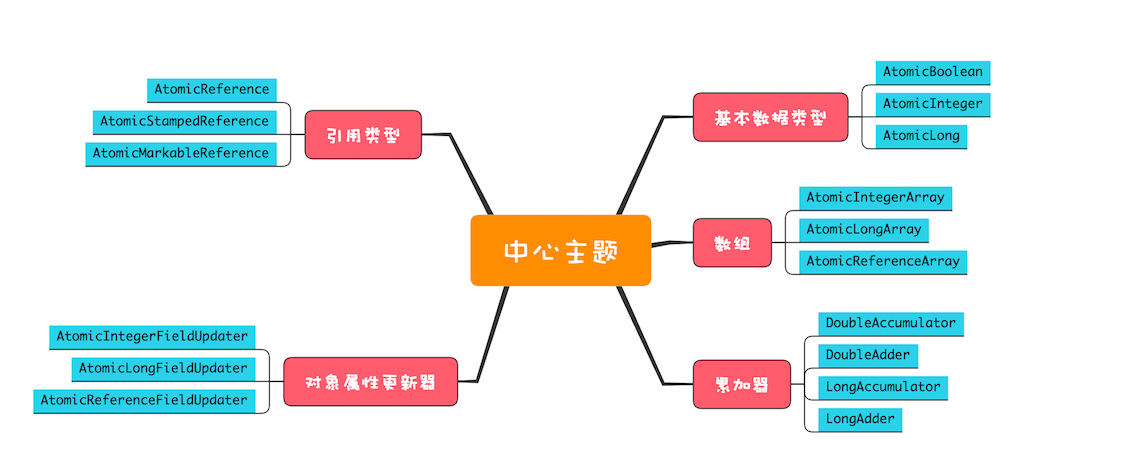
原子类概览
原子化的基本数据类型
AtomicBoolean、AtomicInteger 和 AtomicLong API比较简单
getAndIncrement() //原子化i++
getAndDecrement() //原子化的i--
incrementAndGet() //原子化的++i
decrementAndGet() //原子化的--i
// 当前值+=delta,返回+=前的值
getAndAdd(delta)
// 当前值+=delta,返回+=后的值
addAndGet(delta)
// CAS操作,返回是否成功
compareAndSet(expect, update)
// 以下四个方法
// 新值可以通过传入func函数来计算
getAndUpdate(func)
updateAndGet(func)
getAndAccumulate(x,func)
accumulateAndGet(x,func)原子化的对象引用类型
AtomicReference、AtomicStampedReference 和 AtomicMarkableReference,可以实现对象引用的原子化更新。
AtomicReference 提供的方法和原子化的基本数据类型差不多。
对象引用的更新需要重点关注 ABA 问题,AtomicStampedReference 和 AtomicMarkableReference 这两个原子类可以解决 ABA 问题。
每次执行 CAS 操作,附加再更新一个版本号,只要保证版本号是递增的,那么即便 A 变成 B 之后再变回 A,版本号也不会变回来(版本号递增的)。
boolean compareAndSet(
V expectedReference,
V newReference,
int expectedStamp,
int newStamp) 原子化数组
AtomicIntegerArray、AtomicLongArray 和 AtomicReferenceArray,这样可以原子化地更新数组里面的每一个元素。
这些类提供的方法和原子化的基本数据类型的区别是:每个方法多了一个数组的索引参数。