倒排索引
倒排索引或反向索引(Inverted Index),是一种索引数据结构。与倒排索引相对的叫正排索引或正向索引(forward index)。
现在借助阐述正排索引来更好理解倒排索引。
正排索引
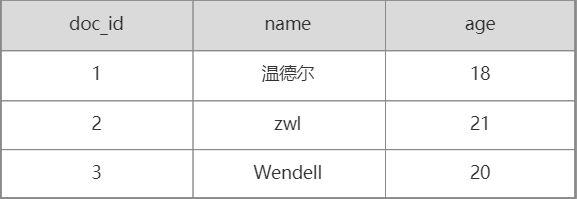
如上图,我们可以通过doc_id =2很快查到{"name":"zwl","age":21}这条数据。
这意味着我们可以通过doc_id很快查到一个具体的数据对象。
Document words
doc1 hello, sky, morning
doc2 tea, coffee, hi
doc3 greetings, sky或如上面所示,假设我们有3个文档,我们将文档和文档中的单词建立映射关系。
这样我们可以通过文档ID,快速得到这篇文档中有哪些单词。
但是,如果要找出有哪些文档中有sky这个单词,就需要查找所有文档,将有对应单词的文档汇总起来,这无疑是一种很低效的过程。
像上面举的例子,将文档ID与文档内容映射起来的数据结构,称为正排索引。
正排索引,本质是通过key来查找value,可以理解为一种散列表的形式。
如果我们想要在一个博客网站中,找到哪些博客的内容里有单词rich,将所有博客内容遍历再汇总的方法,时间成本很高,实际业务中肯定无法接受。
这种场景就非常适合倒排索引。
倒排索引
既然正排索引是文档映射单词,通过文档查找单词,那么触类旁通,倒排索引就是单词映射文档,通过单词找到文档。
对于上面的3个文档,我们重建一种数据结构,左边是单词,右边是这个单词在哪个文档里出现。
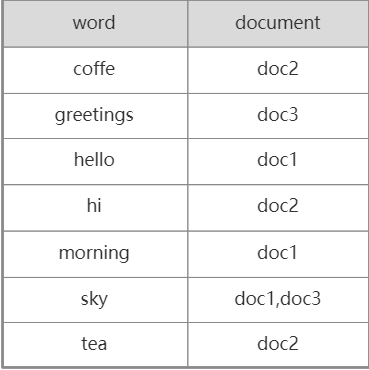
这时候我们将单词和文档ID映射起来,此时再查找哪些文档中含有sky,就能很快搜索到结果,即[doc1,doc3],再通过ID就可以找到对应的文档。
这种结构就是倒排索引。
由倒排索引,引出来一些相关的术语和概念。
文档 Document
document本质是以文本形式存在的数据对象。但像谷歌,百度这种搜索引擎,处理的是海量的互联网网页,那么文档的概念就要更宽泛一些,像Word,PDF,XML,HTML都属于文档,或者一条微博,一封邮件都属于文档范畴。
文档ID Document ID
文档存储进互联网系统内部,都会为其赋值一个ID,来作为这个文档的唯一标识,通过doc_id,快速的查找文档。
倒排列表 Posting list
上图中,document就是一个posting list,posting list记录了出现过某个单词的所有文档以及该单词出现在该文档的位置的信息。根据posting list,即可知道哪些文档包含指定单词。posting list由倒排索引项组成。
- 倒排索引项
- 文档ID
doc_id - 词频
TF该单词在文档中出现的次数,用于文档的相关性评分 - 位置
position单词在文档中分词的位置,可以用来语句搜索(phrase query) - 偏移
offset记录单词的开始和结束位置,可以用来高亮显示
- 文档ID
单词词典 Term Dictionary
term dictionary即包含了系统所存储的所有文档中出现的单词,每个单词会指向对应的倒排列表。
term dictionary一般比较大,可以通过B+数或者哈希拉链法实现,以满足高性能的查询。
单词索引 Term Index
term dictionary包含了所有文档出现的所有单词,往往是很大的。很难放到内存中来提供程序查询,但放到磁盘上,多次的IO又降低了查询的性能。
因此产生了term index,term index就是对term dictionary进行索引,将占用空间小的term index放入内存中,方便我们快速的查找term dictionary。
分词 Analysis
如何正确地区分文档中的单词,并和term dictionary形成映射,这一过程成为分词。
举例:Apple is a company. And i like eat apples.这句话可以分词为apple/is/a/company/and/i/like/eat,apple&apples由于在搜索中几乎没有影响,我们可以全分到单数形式。
结构图
基于上面的概念,我们可以画一个倒排索引在实际应用中大概的结构图。
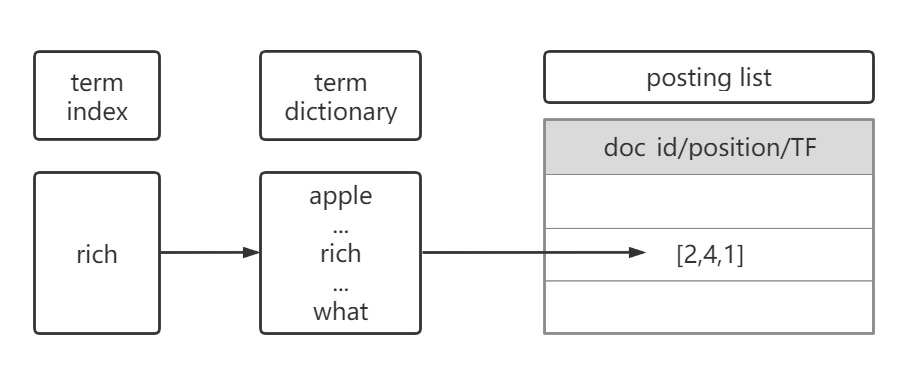
假设某文档doc_id=2,其内容是i am a rich man.
那么如下图,我们通过term index找到term diciionary中rich,再通过rich指向的posting list,找到对应的信息。
对应的信息包含了doc_id为2,出现的位置(offset)是4,词频TF是1。根据posting list的信息,我们就可以找到目标文档。
Lucene中的应用
Elasticsearch是构建在Apache Lucene之上的分布式搜索引擎。
现在来看下Lucene中的倒排索引是如何构成的,基本的结构其实就是这样:

我们通过一个例子来进一步理解:
假如我们有一些人名的term:
cindy,debbie,erwin,bob,adele
我们要为它们构建posting list。
但是如果按这样的顺序在term dictionary中查找,由于是无序的,无疑是很慢的。
如果在排序之后:
adele,bob,cindy,debbie,erwin
我们就可以用二分查找的方式,能够比全部遍历更快地找出目标term,通过O(logN)次磁盘查找得到目标。
但是磁盘IO是非常昂贵的,所以要尽量少读盘。
因此必要把一些数据放入内存中。但是又因为term dictionary太大了,无法完整放入内存中,就需要有term index。
Term Index的数据结构
term index实际实现是trie树。(关于trie tree请点击这里)
这棵树不会包含所有的term,它包含的是一些term的前缀,这样可以通过它快速定位到以某些前缀开头的单词的offset,定位好之后,再从定位的位置查找term dictionary。
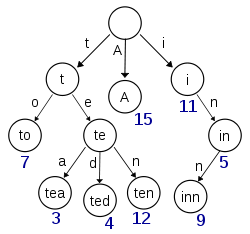
这种数据结构,再加上压缩技术(Lucene Finite State Transducers),term index可以只有所有term的几十分之一,以实现能够将term index放入内存中。
多字段查询下的优化
如果一个查询,我们要求查询内容包含name = cindy and age = 18的文档,我们可能得到以下的数据。
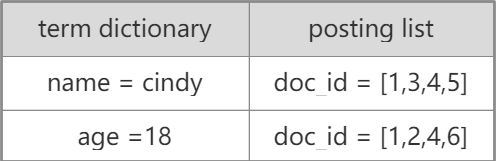
显然,满足条件的数据是doc_id = [1,4]。
我们应该如何找到满足条件的数据?
最直接的办法,遍历所有满足条件的doc_id集合,找出重复的doc_id,这种方式的效率明显很低。
有两种优化的办法:
- 使用
skip list数据结构,同时遍历name和age的posting list,互相skip - 使用
bitmap数据结构,对name和age两个posting list分别求出bitmap,两个bitmap做与操作
利用skip list
假设我们查询条件为name = zwl and age = 18 and gener = male,得到的结果是3个posting list的文档结果如下:
name = zwl的结果 [3,4,5,6]
age = 18的结果 [1,3,5]
gender = male的结果 [2,3,4,5,9]
很明显,得到的正确结果应该是doc_id = [3,5]
现在来看下Lucene中是如何利用skip list来取出交集的:
将3个
posting list抽象化成节点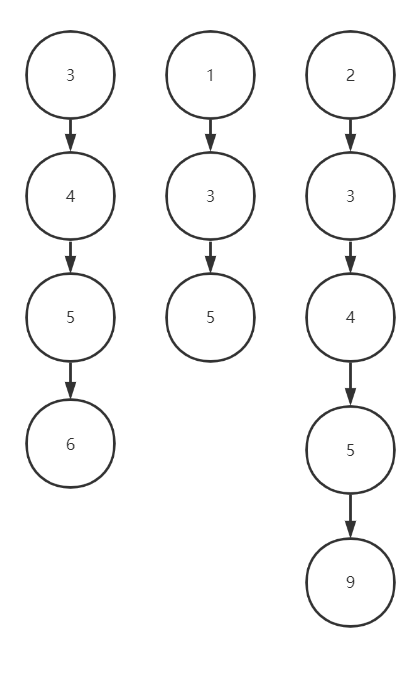
维护一个链表,里面存储每个
posting list的第一个节点,并将存储的节点按doc_id由小到大排序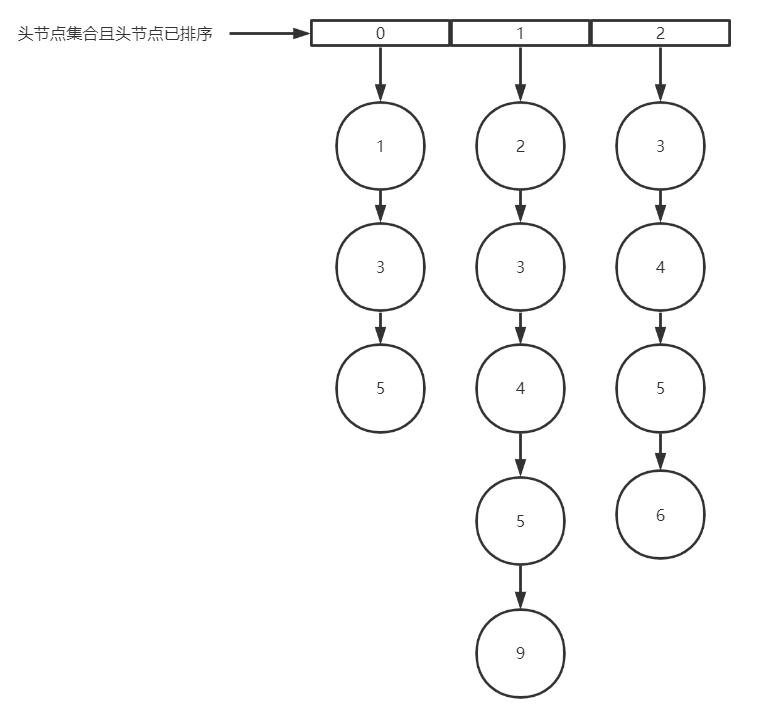
维护两个指针,一个为
min指针,从最小的节点开始从左向右移动,一个为max指针,固定在doc_id最大的节点
此时,指针
min指向doc_value=1的节点,与max指向的doc_value=3比较,因为如果想要取得交集,至少需要有doc_id=3的节点。在这里我们可以把第一个
posting list中doc_id<3的全部移除,让3成为第一个节点,接着min移向下一个节点
同样,2也无法与3取得交集,重复第4步,此时
min走到了最后一个节点,第一轮比较完成,我们发现第一行都是doc_id=3,则3是我们取到的第一个交集。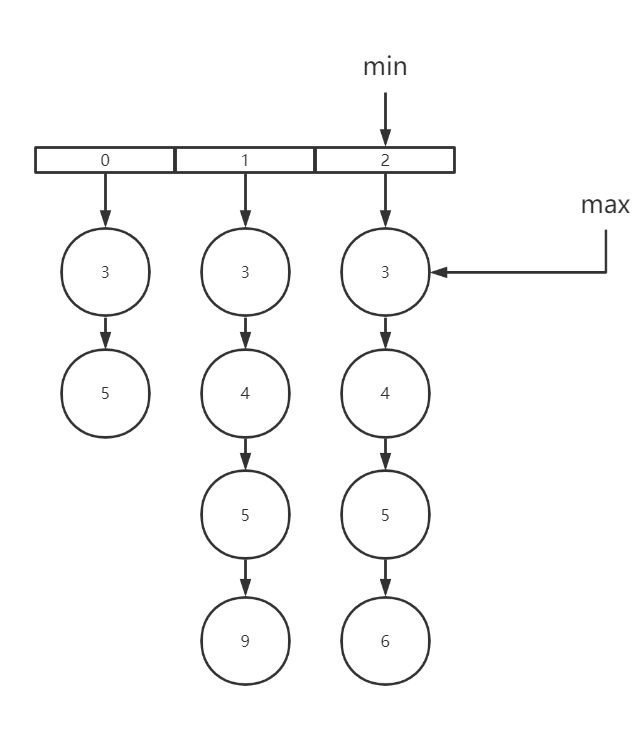
接着我们重新排序,重复上面的步骤,此时
min= 4,max=5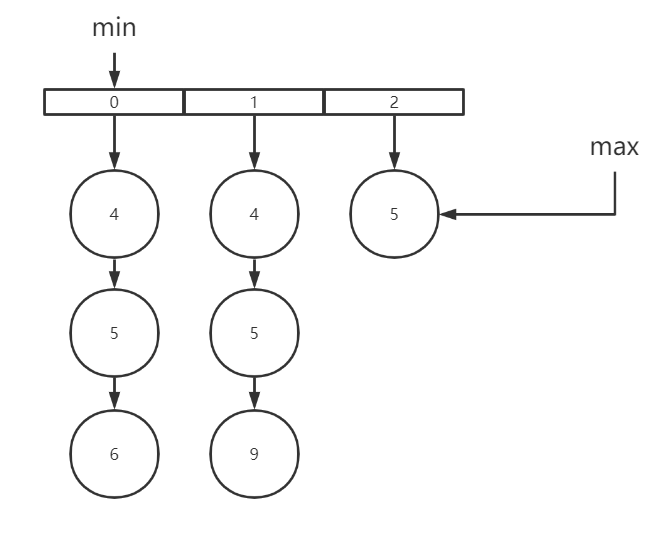
重复步骤,4可以直接移除,5可以保留,最后得到交集
[3,5]
这样,利用跳表的思想,可以很快跳过哪些无法取得交集的节点,快速实现取得交集。
利用bitmap
利用bitmap的思想要更直观一些。
比如
posting list1 = [1,3,4,7,10],用bitmap表示就是[1,0,1,1,0,0,1,0,0,1]
posting list2 = [3,4,7],bitmap就是[0,0,1,1]
两个bitmap进行AND操作就能得到交集[0,0,1,1],即doc_id = [3,4]
bitmap自身就有压缩的特点,其用一个byte就可以代表 8 个文档。所以 100 万个文档只需要 12.5 万个byte。但是考虑到文档可能有数十亿之多,在内存里保存
bitmap仍然是很奢侈的事情。而且对于个每一个
filter都要消耗一个bitmap,比如 age=18 缓存起来的话是一个bitmap,18<=age<25是另外一个filter缓存起来也要一个bitmap。所以秘诀就在于需要有一个数据结构:
- 可以很压缩地保存上亿个
bit代表对应的文档是否匹配filter;- 这个压缩的
bitmap仍然可以很快地进行AND和OR的逻辑操作。
Lucene使用的这个数据结构叫做Roaring Bitmap。
其压缩的思路其实很简单。与其保存 100 个 0,占用 100 个
bit。还不如保存 0 一次,然后声明这个 0 重复了 100 遍。
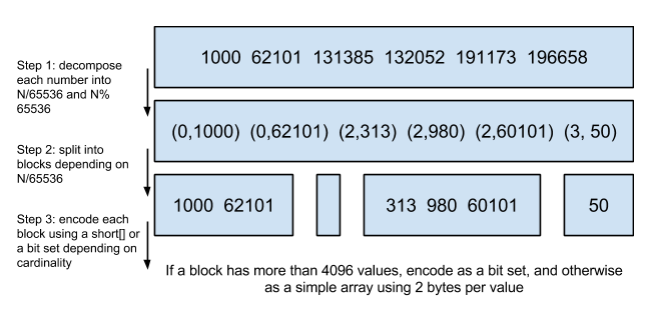
关于两种方式性能的对比,Elasticsearch官方做了详细的对比,详情点击这里。
总的来说,跳表的效率要比bitmap好。
Term Index与MySQL B+树的比较
MySQL只有term dictionary这一层,是以b+ tree排序的方式存储在磁盘上的。检索一个
term需要若干次的random access的磁盘操作。而
Lucene在term dictionary的基础上添加了term index来加速检索,term index以树的形式缓存在内存中。从
term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘random access次数。term index在内存中是以FST(finite state transducers)的形式保存的,其特点是非常节省内存。term dictionary在磁盘上是以分block的方式保存的,一个block内部利用公共前缀压缩,比如都是Ab开头的单词就可以把Ab省去。这样
term dictionary可以比b-tree更节约磁盘空间