Elasticsearch索引流程
分片
分片是Elasticsearch中最小的工作单元,本质上是一个Lucene的Index。
对于一个Lucene Index它在ES中的基本结构是这样:
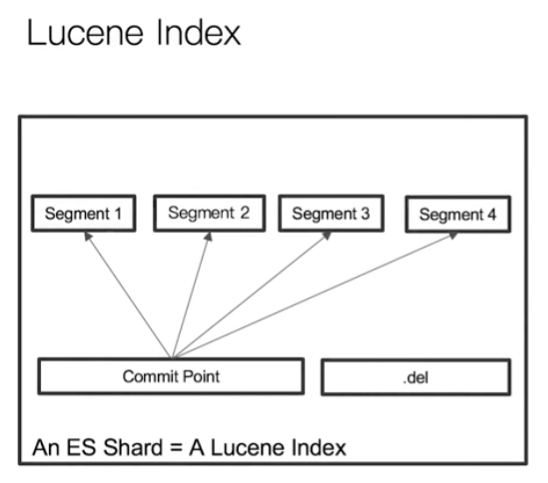
一个Lucene Index中,单个倒排索引文件被称为Segment,其包含多个Segment,Segment是不可变更的。
在分片中查询时,会一次查询所有的Segment,然后汇总数据并返回。
Lucene中有一个Commit Point文件,用来记录所有Segment的信息。另外一个是.del文件,该文件记录了被删除的文档的信息。
索引步骤
当一个文档被写入时,它会经历以下几个步骤:refresh –> flush –> merge。
refresh
当文档最初被写入时,会被写入一个叫Index Buffer的数据结构中,Index Buffer存在于JVM内存中。
此时文档是无法被搜索到的,它只是一个buffer,还没有形成倒排索引。
接着,ES会默认每隔1秒将Index Buffer清空,写入到Segment中,上面说了Segment就是一个倒排索引。
因此,此时文档已经被索引,即可以被搜索。
将Index Buffer写入到Segment的过程,就是refresh。
refresh的触发条件:
- 通过**
index.refresh.interval**控制refresh的执行时间间隔,默认是1秒。这也是为什么ES被称为近实时搜索的原因,因为数据要1秒后才能被搜到。- 如果
Index buffer空间被占满,也会触发refresh,即使执行时间间隔没到。Index buffer默认空间大小时JVM大小的10%Note:
可以通过API,进行手动
refresh,使得数据能够立即被搜索到。
flush
文档数据被写入Index buffer的同时,也会写入一个叫Transaction log(每个分片有一个)的文件中,这个文件存在的目的是为了保证ES数据的正确性。
Transaction log这个文件,默认每5秒落一次盘,并且是顺序写。在ES断电重启时,会从这个文件中恢复数据进行recover。
但由于这个文件是5秒落一次盘,因此重启了还是可能丢掉5秒的数据。不过这个落盘间隔是可以配置的,最小是100ms。
显然,配置的落盘时间越小,数据准确性就越高,但同样会带来更多的性能成本。
默认每隔30分钟或者Transaction log满(默认512M)的时候,会触发flush。
当flush发生时,会执行以下几个步骤:
- 调用一次
refresh,清空index buffer,将其写入segment - 调用
fsync,将内存中的Segment写入到磁盘 - 清空
Transaction log,将其写入磁盘
merge
merge是ES定期自动执行的
merge操作主要做的内容:
- 将多个segment合并成一个
- 将.del文件中要删除的文档进行一个真正的删除
手动
merge:
POST my_index/_forcemerge
merge优化
merge实际上是一个比较重的操作,因此我们需要着手去优化。
本质上,merge就是将多个Segment合并成一个大的Segment。
如果Segment产生的太多太快,就会导致merge频繁发生,影响性能。
因此我们有2个方向可以优化:
降低分段产生的数量和频率:
- 将
refresh interval调整到分钟级别/indices.memory.index_buffer_size大小调大 - 尽量避免文档的更新操作
降低最大分段的大小,避免较大的分段继续参与merge,节省系统资源。(最终会有多个分段)
index.merge.policy.segments_per_tier默认为10,越小需要越多的合并操作该属性指定了每层段的数量。较少的值带来较少的段。这意味着更多的合并操作,和更低的索引性能,默认值为10,其值应该不低。
index.merge.policy.max_merged_segment默认5GB 超过此大小后,就不再参与后续的合并操作
其他优化点:
当一个
index不再有写入操作时,建议对其进行force merge提升查询速度,减少内存开销
POST my_index/_forcemerge?max_num_segments=1GET _cat/segments/my_index?v最好
force成一个Segment,但是force merge会占用大量网络/IO/CPU如果不能在业务高峰期前
merge完,就需要增大最终的分段数调整分片的大小/
index.merge.policy.max_merged_segment大小
tips
- 若要优化索引速度,而不注重实时性,可降低
refresh频率 - 当数据从hot移动到warm,官方建议手动执行以下
force merge - 当节点数据量很大时,有重启节点的需要时,建议先手动
flush,会节省很多时间 Transaction log落盘的频率影响了数据的安全性refresh的频率影响了数据的实时性



