前置
Discovery
Discovery是集群组成模块寻找形成集群的其他节点的过程。
当你启动一个es节点或者一个节点认为master节点挂掉时这个过程就会开始执行了,直到master节点被找到或者选举出一个新master节点。
这个过程从来自一个或多个seed hosts providers提供的seed addresses开始,这些地址还包括最后一个被发现集群的master-eligible节点中的任何一个地址。
这个过程包含两步:
- 每个节点通过连接
seed addresses中的地址来进行探测,并且尝试去认证它连接到的节点,看是探测到的节点否是一个master-eligible节点 - 如果是
master-eligible,它会探测到的这个master-eligible节点分享它已经发现的所有master-eligible节点,对方节点也会分享它自己同等的信息。然后节点根据获取到的信息,继续探测它没探测过的节点,获取它们的master-eligible节点列表。
如果某个节点不是master-eligible节点,那么它会继续这个Discovery过程直到它找到master节点。如果一直没有master节点被选出来,那么这个节点会隔discovery.find_peers_interval时间重试,默认1s。
Quorum-based decision making
选举一个主节点并改变集群状态是所有master-eligible节点必须共同完成的两个基础的任务。即使某些节点挂掉,这些任务也需要能够正常执行。
这种能够正常执行的稳健性,通过仲裁来实现,仲裁节点是master-eligible节点的子集。
只需要节点的子集进行仲裁优势在于:某些节点可能会发生故障,但不会阻止集群继续运行。
仲裁节点是经过认真选择的,因此集群不会出现“脑裂”场景。
随着节点的添加或删除,Elasticsearch 通过更新集群的voting configuration来保持一个最佳的容错水平,voting configuration是一组master-eligible节点,在做出选择新主节点或提交新集群状态等决策时,这些节点的响应会被计算在内。
只有在voting configuration中超过一半的节点做出响应后,才会做出决定。
通常voting configuration中配置的节点集合就是当前集群中所有master-eligible节点的集合。但是在某些情况下,voting configuration中配置的节点可能会有所不同。(具体看完下文你就懂了)
为确保集群保持可用,不能同时停止voting configuration中的一半或更多节点。只要超过一半的投票节点可用,集群仍然可以正常工作。
这意味着如果有三个或四个master-eligible节点,集群可以容忍其中一个不可用。如果有两个或更少的符合主节点条件的节点,它们必须全部保持可用。
在一个节点加入或离开集群之前,master节点必须提交一个集群状态更新来调整voting configuration,这个过程会花费短暂的时间。
在移除更多节点前,等待这个过程完成很重要。
Master elections
Elasticsearch uses an election process to agree on an elected master node, both at startup and if the existing elected master fails.
任何master-eligible节点都可以开始选举,通常第一次选举会成功。
选举通常只有在两个节点几乎同时开始选举时才会失败,因此Elasticsearch在每个节点上随机安排选举以降低发生这种情况的可能性。
节点会一直重试选举过程,直到选举出一个主节点。最终选举成功(具有任意高的概率)。主选举的调度由master election settings设置控制。
Voting configurations
每个Elasticsearch集群都有一个voting configuration,这个配置项包含的是一组master-eligible节点。当选举新的master节点或者更新集群状态时,
这组节点的响应会被考虑进决策的计算之内。只有大多数(超过半数)节点都投票响应时,才会做出对应的决策。
通常voting configuration的集合就是整个集群中所有的master-eligible节点,在一些特别的情况下回做出调整。
通过下面这个API获取集群当前的voting configuration:
curl -X GET "localhost:9200/_cluster/state?filter_path=metadata.cluster_coordination.last_committed_config&pretty"
有时候
voting configuration中的配置甚至会包括一些不可用节点,可用的节点却不在里面。
在选举master或者更新集群状态这种需要投票做决策的操作中,一般情况下,有资格投票的节点越多越好。所以当有新的master-eligible 节点加入集群时,Elasticsearch倾向于将它加入voting configuration里。另一种情况是,如果集群中,一台属于voting configuration节点下线了,如果此时集群中有不存在于voting configuration的master-eligible 节点存活,Elasticsearch会把那台下线的节点移出voting configuration,把存活的这台加进来。这样保证了voting configuration的弹性。
只有在整个集群第一次启动时才需要初始仲裁。 加入建立群集的新节点可以安全地获取所需的所有信息。节点将在重新启动时将所需的所有信息存储到磁盘中。
下面这段文章复制的,写的不错了,不需要改了。
Raft算法选主流程
其设计原则如下:
- 容易理解
- 减少状态的数量,尽可能消除不确定性
在Raft中,节点可能的状态有三种,其转换关系如下:
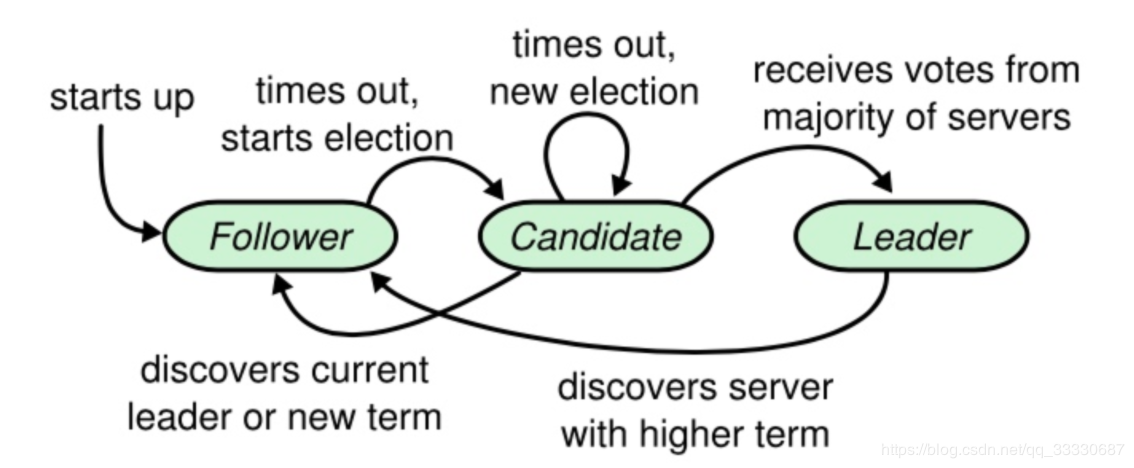
正常情况下,集群中只有一个Leader,其他节点全是Follower。Follower 都是被动接收请求,从不主动发送任何请求。Candidate [ˈkændɪdət; ˈkændɪdeɪt] n. 候选人,候补者;应试者 是从Follower到Leader的中间状态。
Raft中引入任期(term) 的概念,每个term内最多只有一个Leader。term 在Raft算法中充当逻辑时钟的作用。服务器之间通信的时候会携带这个term,如果节点发现消息中的term小于自己的term,则拒绝这个消息;如果大于本节点的term,则更新自己的term。如果一个Candidate或者Leader发现自己的任期过期了,它会立即回到Follower状态。
Raft选举流程为:
- 增加当前节点本地的current term,切换到Candidate状态;
- 当前节点投自己一票,并且并行给其他节点发送RequestVote RPC (让大家投他) ;
然后等待其他节点的响应,会有如下三种结果:
- 如果接收到大多数服务器的选票,那么就变成Leader。成为Leader后,向其他节点发送心跳消息来确定自己的地位并阻止新的选举。
- 如果收到了别人的投票请求,且别人的term比自己的大,那么候选者退化为Follower;
- 如果选举过程超时,再次发起一轮选举;
ES实现Raft算法选主流程
ES实现中,候选人不先投自己,而是直接并行发起RequestVote,这相当于候选人有投票给其他候选人的机会。这样的好处是可以在一定程度上避免3个节点同时成为候选人时,都投自己,无法成功选主的情况。
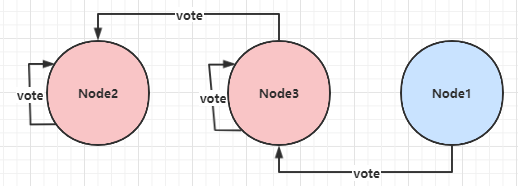
ES不限制每个节点在某个term上只能投一票, 节点可以投多票,这样会产生选出多个主的情况:
- Node2被选为主,收到的投票为:Node2、 Node3;
- Node3被选为主,收到的投票为:Node3、 Node1;
对于这种情况,ES的处理是让最后当选的Leader成功,作为Leader。如果收到RequestVote请求,他会无条件退出Leader状态。在本例中,Node2先被选为主,随后他收到Node3的RequestVote请求,那么他退出Leader状态,切换为CANDIDATE,并同意向发起RequestVote候选人投票。因此最终Node3成功当选为Leader。
动态维护参选节点列表
在此之前,我们讨论的前提是在集群节点数量不变的情况下,现在考虑下集群扩容、缩容、节点临时或永久离线时是如何处理的。在7.x之前的版本中,用户需要手工配置minimum_master_nodes, 来明确告诉集群过半节点数应该是多少,并在集群扩缩容时调整他。现在,集群可以自行维护。
在取消了discovery.zen.minimum_master_nodes 配置后,现在的做法不再记录“quorum”法定数量的具体数值,取而代之的是记录一个节点列表,这个列表中保存所有具备master资格的节点(有些情况下不是这样,例如集群原本只有1个节点,当增加到2个的时候,这个列表维持不变,因为如果变成2,当集群任意节点离线,都会导致无法选主。这时如果再增加一个节点,集群变成3个,这个列表中就会更新为3个节点),称为VotingConfiguration,他会持久化到集群状态中。
在节点加入或离开集群之后,Elasticsearch 会自动对VotingConfiguration 做出相应的更改,以确保集群具有尽可能高的弹性。在从集群中删除更多节点之前,等待这个调整完成是很重要的。你不能一次性停止半数或更多的节点。(感觉大面积缩容时候这个操作就比较感人了,一部分一部分缩)。默认情况下,ES自动维护VotingConfiguration。有新节点加入的时候比较好办,但是当有节点离开的时候,他可能是暂时的重启,也可能是永久下线。你也可以人工维护VotingConfiguration,配置项为:cluster.auto_shrink_voting_configuration,当你选择人工维护时,有节点永久下线,需要通过voting exclusions API将节点排除出去。如果使用默认的自动维护VotingConfiguration,也可以使用voting exclusions API来排除节点,例如一次性下线半数以上的节点。
如果在维护VotingConfiguration时发现节点数量为偶数,ES会将其中一个排除在外,保证VotingConfiguration是奇数。因为当是偶数的情况下,网络分区将集群划分为大小相等的两部分,那么两个子集群都无法达到“多数”的条件。
Voting configuration exclusions API
POST /_cluster/voting_config_exclusions?node_names=<node_names>
POST /_cluster/voting_config_exclusions?node_ids=<node_ids>
DELETE /_cluster/voting_config_exclusions
Adds nodes named nodeName1 and nodeName2 to the voting configuration exclusions list:
POST /_cluster/voting_config_exclusions?node_names=nodeName1,nodeName2
Remove all exclusions from the list:
DELETE /_cluster/voting_config_exclusions参考
Elasticsearch Guide [7.15] » Set up Elasticsearch » Discovery and cluster formation » Discovery


